2023. 6. 10. 22:33ㆍ뚝딱뚝딱 만들기 Devlog/프로젝트 Devlog
소프트웨어 마에스트로에서 진행하는 프로젝트를 위해 사진 데이터를 모을 일이 있어서,
여러 시행착오를 통해 Flickr 공식 API를 활용한 사진 크롤러를 개발했습니다.
Github 링크 : https://github.com/Hana-Dul-Set/flickr-crawler
GitHub - Hana-Dul-Set/flickr-crawler: Simple flickr crawler for downloading images by text similar to website's search results,
Simple flickr crawler for downloading images by text similar to website's search results, using flickr's APi with python. - GitHub - Hana-Dul-Set/flickr-crawler: Simple flickr crawler for d...
github.com
README에도 나와있듯이, crawler.py의 설정을 변경하고 실행하면 다운로드가 시작됩니다.
주요 기능
- Flickr.com에서 사진을 검색할 때 얻는 결과와 똑같은 결과의 이미지를 다운받습니다.
- API 요청을 날릴 때마다 사진이 중복되서 오는 경우가 잦은데, 중복되는 다운로드를 방지합니다.
- 이미지를 다운받을 때 1024~640 크기의 이미지를 받을 수 있으면 해당 크기를 받습니다.
- 시간당 3600 request를 보낼 수 있으므로, 매 리퀘스트마다 1초씩 쉽니다.
- API에서 같은 param으로 4000장 이상의 사진을 받으려하면 같은 사진을 계속 줍니다. 이를 막기위해 이분 탐색으로 시간을 좁혀가며 4000장이 넘는 사진을 얻을 수 있게 했습니다.
- 요청 실패나 에러가 발생해도 꺼지지 않으며, 작동 로그를 파일로 남깁니다.
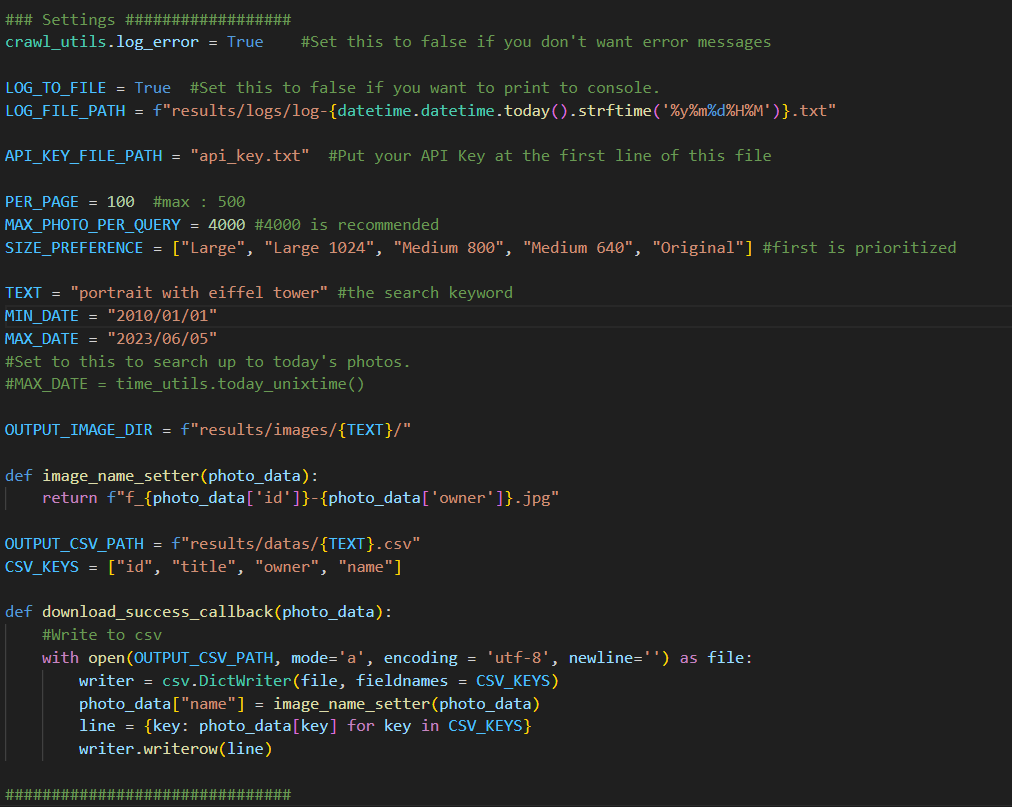
핵심인 crawler.py에 있는 설정 부분입니다.
이 곳에서 검색 키워드, 선호 사이즈, 탐색 날짜 범위, 이미지 이름 포매팅 등을 할 수 있습니다.
'뚝딱뚝딱 만들기 Devlog > 프로젝트 Devlog' 카테고리의 다른 글
| 23.03.06 포켓몬 9세대 실시간 대미지 계산기 개발 (0) | 2023.03.06 |
|---|---|
| 22.07.13 중간 프로토타입 (BIC 제출 버전) (0) | 2022.07.14 |
| 22.05.03 개발 근황 (0) | 2022.05.03 |
| 22.04.01 효과 / 점수 추가 (0) | 2022.04.01 |
| 22.03.06 - 카드게임 개발 시작 (0) | 2022.03.06 |