2021. 2. 8. 23:07ㆍ배움엔 끝이없다/머신러닝
kaist.edwith.org/machinelearning1_17/lecture/40603
카이스트 문일철 교수님의 인공지능 및 기계학습 개론 강의입니다.
인공지능 쪽은 정말 하나도 모르지만, 이걸로 시작해보기로 했습니다.
우선은 이해한 대로 쭉 기록해 두고, 배우면서 잘못 알고 있던 점은 수정하는 방식으로 글을 써보겠습니다.
1. Rule based learning
고전적인 머신 러닝의 방식 중 하나인 Rule based learning은
세상의 모든 현상은 특정한 시스템을 따르기 때문에 그 규칙을 습득하면 된다는 이론입니다.
문장으로 표현하면 'A, B, C, ... 면 Y다'라는 형식을 가집니다.
예를 들어 "점심을 안 먹었으면, 저녁을 일찍 먹는다"의 형식입니다.
이 이론은 몇 가지 전제를 가집니다.
1. 관측된 데이터엔 error나 noise가 없다.
2. random한 데이터는 없다.
3. 관측된 데이터들만으로 정확한 규칙을 만들 수 있다.
-체육활동 예시
위의 전제를 만족한다고 가정하고 밖에서 체육활동을 해도 되는지에 대한 traning data(\(D\))를 만들어 보겠습니다.
1. 기온: warm / 비: X / 바람 : X / 미세먼지 : low → 해도 된다
2. 기온: warm / 비: O / 바람 : X / 미세먼지 : low → 해도 된다
3. 기온: cold / 비: X / 바람 : X / 미세먼지 : high → 하면 안 된다
-가설(Hypothesis) 세우기
가설은 어떤 instance(상황)를 input으로 해 원하는 결과를 도출하는 함수입니다.
모든 instance들 \(X\)에 대해 알맞은 결과를 도출하는 가설 \(c\)를 구하는 것이 목표입니다.
1번 데이터를 만족하는 어떤 가설 \(h\)를 이렇게 표현할 수 있습니다.
$$h_1 : <warm/X/X/low> → yes$$
기온이 따듯하고 비가 오지 않고 바람이 불지 않고 미세먼지가 적은 경우 체육활동을 해도 됩니다.
하지만 2번 데이터까지 참고하면 아래처럼 가설을 세울 수 있습니다.
$$h_2 : <warm/?/X/low> → yes$$
여기서 물음표는 don't care라는 의미로, 어떤 값이 와도 상관없다는 뜻입니다.
2. Version Space
Version Space는 어떤 데이터들에 대해 참인 가설들의 집합입니다.
예를 들어 위에서 구한 \(h_2\) 외에도 아래와 같은 참인 가설을 세울 수 있습니다.
$$h_3 : <?/?/X/low> → yes$$
이는 모든 instance의 데이터(\(3^4\)개)를 갖고 있지 않아서 \(h\)가 하나로 정해지지 않기 때문입니다.
이렇게 주어진 데이터들에 대해 참인 여러 가지 가설들을 모두 묶어서 Version Space라고 합니다.
Version Space를 정의하는 방법은 가장 specific한 가설과 가장 general한 가설을 찾는 것입니다.
specific과 general의 개념은 부분집합의 개념이랑 비슷한데요,
예를 들어 \(h_1\)보다 \(h_2\)가 yes로 나오는 instance의 수가 더 많습니다.
이럴 경우 \(h_1\)이 specific한 가설, \(h_2\)가 general한 가설이 되고, \(h_1 < h_2\)라 표현할 수 있습니다.
모든 데이터에 대해 참인 가설들을 \(H\), 그중 가장 general한 가설을 \(g\), 가장 specific한 가설을 \(s\)라 하면,
Version Space를 아래처럼 정의할 수 있습니다.
$$VS_{H,D}=\{h \in H | g \ge h \ge s \}$$
3. Candidate Elimination Algorithm
Candidate Elimination Algorithm은 Version Space를 구하는 알고리즘입니다.
방식은 가장 specific한 함수 S와 가장 general한 함수 G를 찾아가는 방식으로, 위에서 했던 방식과 유사합니다.
처음에 이렇게 정의합니다.
$$ S=<∅,∅,∅,∅>, G=<?,?,?,?> $$
여기서 ∅은 무조건 no라는 뜻입니다.
S는 무조건 no를 도출하는 가설이고, G는 무조건 yes를 도출하는 가설이니 각각 가장 specific하고 가장 general합니다.
방식을 의사코드로 나타내면 이렇습니다.
for instance \(x\) in \(D\)
if x의 결과가 yes면 : S가 x를 포함하도록 수정, G에서 x를 no로 만드는 가설 제외
if x의 결과가 no면 : G가 x를 빼도록 수정, S에서 x를 yes로 만드는 가설 제외
즉 S를 점점 general하게 하고, G를 점점 specific하게 만들어 Version Space를 점점 좁혀가는 겁니다.
-Version Space와 Candidate Elimination의 한계
Version Space의 개념을 이용한 Candidate Elimination Algorithm은 한계를 가집니다.
우선 Rule based learning의 전제를 만족하는 일은 세상에 거의 없고,
또 가설이 하나로 정해지지 않고 Version Space가 존재하기 때문에 새로운 데이터를 분류할 수 없을 수 있습니다.
4. Decision Tree
Decision Tree는 조건들의 나열로 가설 함수 \(h\)를 만들지 않고 하나의 트리로 구성합니다.
위의 예시에서 \(h_3 : <?/?/X/low> → yes\)를 Decision Tree로 표현하면 아래와 같습니다.
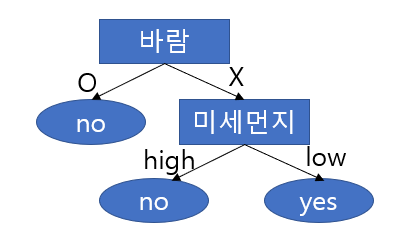
55개의 positive result와 45개의 negative result를 가지는 데이터셋을 분류하는 Decision Tree 예시입니다.
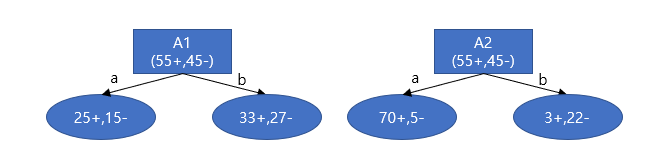
A1과 A2는 바람과 미세먼지와 같은 데이터의 속성(feature),
a, b는 각 속성의 값(value)입니다.
분류된 결과의 25+,15-는 15개의 positive result, 10개의 negative result를 뜻합니다.
예를 들어 A2의 값이 a인 데이터들을 모아놓고 보면 70개의 positive result, 5개의 negative result가 있다는 뜻입니다.
-Entropy(엔트로피)
위 예시에서 A1 속성보다는 A2 속성이 더 효과적인 분류기준이라고 할 수 있습니다.
왜냐하면 A1으로 분류된 결과는 positive와 negative가 골고루 분포돼있어 가설을 세우기 힘든 반면,
A2의 값이 a인 데이터는 negative result 쪽으로 몰려있기 때문입니다.
이런 데이터가 골고루 퍼져있는 정도, 혹은 데이터의 불확실성을 측정하여 엔트로피라고 합니다.
즉, 엔트로피가 높을수록 결과값이 퍼져있어 하나로 정의했을 때 정확도가 낮다는 뜻입니다.
엔트로피를 측정하는 함수 \(H\)는 다음과 같습니다.
$&P(Y=positive)=\frac{55}{45+55}, P(Y=negative)=\frac{45}{45+55}$$
\begin{align*} H(X) &= -\sum_{X}P(X=x)log_bP(X=x) \\\\ H(Y|X) &= \sum_{X}P(X=x)H(Y|X = x) \\ &=\sum_XP(X=x)\{-\sum_YP(Y=y|X=x)log_bP(Y=y|X=x)\} \end{align*}
식이 잘 이해가 안 가니 예시를 하나씩 들어보겠습니다.
우선 Y는 어떤 결과들(positive/negative)을 나타내고, X는 속성(A1/A2/...)를 나타냅니다.
\(H(Y)\)를 계산하는 건 데이터들의 결과값이 얼마나 불확실한지(고르게 퍼져있는지)를 계산하는 겁니다.
계산은 (어떤 Y값의 확률)*log(어떤 Y값의 확률)을 모든 Y값에 대해 해주면 됩니다.
로그의 밑 b는 result 값의 종류 수가 들어가는 것 같습니다.
예를 들어 위의 예시에서 \(H(Y)\)를 계산하면 아래와 같습니다.
\begin{align*}\\H(Y)&=-(P(Y=positive)log_2P(Y=positive)+(P(Y=negative)log_2P(Y=negative))\\&=-(\frac{55}{100}log_2\frac{55}{100}+\frac{45}{100}log_2\frac{45}{100})\end{align*}
그 다음 식인 조건부 엔트로피는 속성으로 분류된 결과들의 엔트로피를 각각 측정해 더해주면 됩니다.
$$H(Y|A1) = H(Y of A1=a) + H(Y of A1=b)$$
만약 \(A_i\)의 값이 여러 개라면 각 하위노드의 엔트로피에 가중치를 곱한 값의 평균을 사용합니다. 가중치는 각 분류된 노드의 데이터 개수입니다.
$$H(Y|A1) = Average(H(Y of A1=a)*w_a + H(Y of A1=b)*w_b + ...)$$
-Information Gain(정보 이득)
정보 이득은 어떤 속성을 선택해서 얻을 수 있는 이득입니다.
만약 A1 속성을 사용한 엔트로피가 A1 속성을 사용하지 않았을 때의 엔트로피보다 크다면 사용하지 않습니다.
속성 \(A_i\)를 활용했을 때 정보 이득 \(IG(Y,A_i)\)은 아래와 같습니다.
$$ IG(Y,A_i)=H(Y)-H(Y|A_i)$$
5. ID3 알고리즘
ID3 알고리즘은 Decision tree를 만들어내는 알고리즘 중 하나입니다.
기본적으로는 상위 노드에 가장 정보이득이 높은 속성을 배치하고, 남은 속성 중에서 하위 노드에 대해 가장 정보이득이 높은 속성을 하위 노드에 배치하는 식입니다.

위 과정에 부연 설명을 하자면, 첫 번째 속성은 정보이득이 가장 높은 A3으로 정해졌습니다.
그다음 하위 노드인 A3=a를 분류할 속성으로는 그 단계에서 정보이득이 가장 높은 A1으로 정해졌습니다.
A1=a인 노드에는 16개의 positive인 instance들뿐이기 때문에 A3=a이고 A1=a면 positive라고 예측할 수 있습니다.
다음 과정으로는 A1=b의 노드에 분류 속성을 정해주고, A3=b의 분류속성을 정해주고...를 모든 노드가 positive 혹은 negative로 결론 날 때까지 반복하면 됩니다.
하지만 A3=a고 A1=b인 노드의 경우 1개의 instance를 제외하면 모두 negative이기 때문에, negative 노드로 정하고 1개의 예외 instance가 있는 거로 처리해도 됩니다. 이는 사용자가 원하는 대로 설계하면 됩니다.
6. 머신러닝 모델 설계 시 유의할 점
이게 정말 중요한 내용 같은데, 위 알고리즘을 사용해 하위 노드를 계속 추가해 예외 instance를 점점 줄여나갈 수 있습니다.
어느 정도 수준까지는 새로운 데이터(wild data)에 대한 분류 정확도가 높아지지만 계속 복잡한 트리를 만들수록(노드를 추가할수록) 새로운 데이터를 분류하려 할 때 error rate가 높아집니다.
그 이유는 너무 데이터 셋에 특화된 모델을 만들었기 때문에, 그 데이터 셋에 포함된 노이즈들까지 분류 기준에 큰 영향을 준 것입니다.
그렇기 때문에 머신러닝 모델을 설계할 땐 traning data에 대한 error rate를 줄이는 것보다 문제 해결을 위한 학습에 더 중점을 둬야 합니다.
'배움엔 끝이없다 > 머신러닝' 카테고리의 다른 글
| [논문 읽기] Where and Who? Automatic Semantic-Aware Person Composition (0) | 2023.08.28 |
|---|---|
| [논문 읽기] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (0) | 2023.07.20 |
| [논문 읽기] Camera View Adjustment Prediction for Improving Image Composition (0) | 2023.07.01 |
| 인공지능 관련 용어정리 (0) | 2021.10.22 |
| 머신러닝 배워보자 (1) MLE와 MAP (0) | 2021.02.04 |