2023. 7. 20. 14:31ㆍ배움엔 끝이없다/머신러닝
논문 제목 : MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
저자 : Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam
arxiv 등록일 : 2021/04/15
링크 : https://arxiv.org/abs/1704.04861
요약
일반적인 CNN 모델의 연산/파라미터를 줄이기 위해 Depthwise seperable filter라는 것을 사용함.
만든 것
Depthwise seperable filter
일반적인 D*D convolution 필터는 Dk*Dk*M * Df*Df*N 번 연산을 해야함.
(Dk: 커널크기, M: input 채널, Df: feature크기, N: feature 채널)
한 번의 convolution은 이미지에서 특정 부분을 필터링하고, 채널별로 정보를 합치는 두 단계로 나눠질 수 있음.
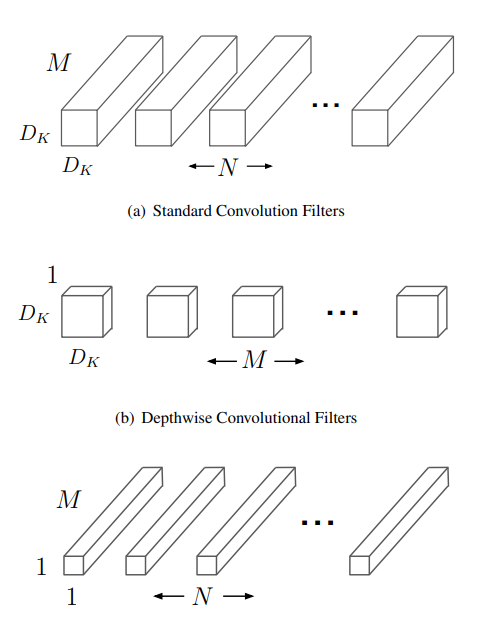
- Depthwise convolution
이미지에 채널별로 커널을 돌림. 즉 output feature의 depth는 M. 연산량은 Dk*Dk*M * Df*Df
- 1*1 convolution
채널끼리의 정보를 합쳐줌. 연산량은 Df*Df * M * N
위 과정을 통해 큰 속도 개선을 얻을 수 있음.
MobileNet
3x3 depthwise convolution을 했기 때문에 약 9배의 속도 증가 효과가 생김.
convolution마다 BatchNorm과 ReLU 레이어를 넣었고 마지막에 fully connected 전에 Average pool 레이어를 넣었음.
대부분의 연산과 파라미터는 1*1 conv 레이어가 갖고있는데, GEMM이라는 함수로 속도를 끌어올림.
모델의 크기를 결정하는 두 가지 하이퍼파라미터 a, p를 제시함
- a(width)는 채널 수에 곱해지는 계수로, 줄일수록 채널 수가 줄어듬
- p(resolution)는 인풋 이미지 해상도에 곱해지는 계수
둘 다 약 제곱배로 파라미터 수를 를 줄여주며, 0.75 밑으로 가면 현저한 성능 하락을 보임
학습 과정
MobileNet은 Tensorflow에서 RMSprop (옵티마이저 종류)을 사용했고 asynchronous gradient descent(멀티프로세싱해도 배치사이즈가 늘지 않는 방법)를 사용해 학습했음.
큰 모델과 다르게 data augmentation이나 regularization을 덜 적용해도 된다.
depthwise filter는 파라미터가 매우 적기 때문에 weight decay는 안하거나 아주 약하게 줘야한다.
여러 Task에 각기 다른 방법의 학습을 사용 (pretrain, distill 등) 했음
- 활용 task : Fine Grained Recognition, Large Scale Geolocation, Face Attributes, Object Detection, Face Embeddings
결론
성능 하락이 1%대로 나오면서 파라미터수는 현저히(약 1/8) 줄어듬.
'배움엔 끝이없다 > 머신러닝' 카테고리의 다른 글
| [논문 읽기] Where and Who? Automatic Semantic-Aware Person Composition (0) | 2023.08.28 |
|---|---|
| [논문 읽기] Camera View Adjustment Prediction for Improving Image Composition (0) | 2023.07.01 |
| 인공지능 관련 용어정리 (0) | 2021.10.22 |
| 머신러닝 배워보자 (2) Decision Tree (Rule Based Learning) (0) | 2021.02.08 |
| 머신러닝 배워보자 (1) MLE와 MAP (0) | 2021.02.04 |