2021. 10. 22. 13:07ㆍ배움엔 끝이없다/머신러닝
인공지능을 다시 공부하기 시작했는데 약어가 너무많아서 익숙하지 않은 상태로 글을 읽으니 이해가 너무 어려웠습니다.
그래서 용어들을 한번 정리하고자 합니다.
퍼셉트론
-인공 신경망에서 노드 하나하나를 말합니다. 뉴런이라고도 합니다.
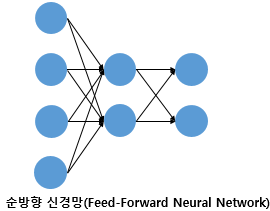
FFNN (Feed Forward Neural Network, 피드 포워드 신경망)
-출력을 입력층에서 출력층으로만 전달하는 신경망
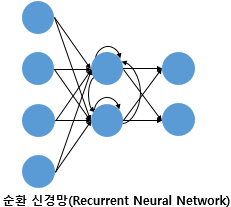
RNN (Recurrent Neural Network, 순환 신경망)
-은닉층의 출력값이 은닉층의 입력으로 사용되기도 하는 신경망
Dense layer (전결합층, Fully-connected layer, FC)
-어떤 층의 모든 뉴런이 이전 층의 모든 뉴런과 연결돼있는 층
활성화 함수 (Activation Function)
-하나의 뉴런의 출력값을 결정하는 함수
-활성화 함수가 선형함수인 은닉층은 여러번 추가해도 1회 추가한 것과 같음
계단 함수
-0이하는 0, 0초과는 1이 되는 함수
하이퍼볼릭 탄젠트 함수
-시그모이드 함수는 0과 1 주변에서 기울기가 0에 가까워지기 때문에 은닉층에서 사용하면 기울기가 잘 전달되지 않음
-그대신 범위가 -1~1이라 조금 나은 하이퍼볼릭 탄젠트 함수를 사용하지만, 기울기 소실 문제는 여전히 있습니다.
ReLU 함수
-f(x) = max(0,x)인 함수로 깊은 신경망에서 많이 사용함
-입력값이 음수면 기울기가 0이라서 죽은 ReLU문제가 있습니다.
Leaky ReLU
-max(ax,x)의 형태로 a는 보통 0.01정도의 값을 가짐
Loss Function (손실 함수)
-실제값과 예측값의 차이를 수치화해주는 함수
MSE (Mean Squared Error)
-오차 제곱 평균
Optimizer (옵티마이저)
-손실 함수의 줄여나가면서 학습하는 방법은 옵티마이저가 결정합니다.
Batch (배치)
-가중치 등 매개변수를 조정하기 위해 사용하는 데이터의 양
배치 경사 하강법 (Batch Gradient Descent)
-전체 데이터를 배치로 사용하며 전체 데이터를 고려하므로 시간과 메모리가 많이 요구되지만 글로벌 미니멈을 찾을 수 있음
확률적 경사 하강법 (Stochastic Gradient Descent, SGD)
-랜덤으로 선택된 하나의 데이터에 대해서만 계산하여 빠르지만 정확도가 낮음
미니 배치 경사 하강법 (Mini Batch Gradient Descent)
-정해진 양의 데이터만 계산해 SGD보다 안정적임
가중치 규제 (Regularization)
-가중치의 절대값을 비용함수에 추가해 가중치가 작게 나오게 하는 방법
Gradient Clipping
-기울기의 폭주를 막기 위해 임계값을 넘지 않도록 자르는 것
세이비어 초기화 (글로럿 초기화)
-가중치 초기화 방식으로, 여러 층의 기울기 분산 사이의 균형을 맞추는 방식
-ReLU 계열 함수를 사용하면 효과가 좋지 않음. 대신 He 초기화를 사용함
'배움엔 끝이없다 > 머신러닝' 카테고리의 다른 글
| [논문 읽기] Where and Who? Automatic Semantic-Aware Person Composition (0) | 2023.08.28 |
|---|---|
| [논문 읽기] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (0) | 2023.07.20 |
| [논문 읽기] Camera View Adjustment Prediction for Improving Image Composition (0) | 2023.07.01 |
| 머신러닝 배워보자 (2) Decision Tree (Rule Based Learning) (0) | 2021.02.08 |
| 머신러닝 배워보자 (1) MLE와 MAP (0) | 2021.02.04 |